UNIVERSR: UNIFIED AND VERSATILE AUDIO SUPER RESOLUTION VIA VOCODER-FREE FLOW MATCHING
Submitted to ICASSP 2026
Authors
Woongjib Choi, Sangmin Lee, Hyungseob Lim, Hong-Goo Kang
Abstract
In this paper, we present a vocoder-free framework for audio super-resolution that employs a flow matching generative model to capture the conditional distribution of complex-valued spectral coefficients. Unlike conventional two-stage diffusion-based approaches that predict a mel-spectrogram and then rely on a pre-trained neural vocoder to synthesize waveforms, our method directly reconstructs waveforms via the inverse Short-Time Fourier Transform (iSTFT), thereby eliminating the dependence on a separate vocoder. This design not only simplifies end-to-end optimization but also overcomes a critical bottleneck of two-stage pipelines, where the final audio quality is fundamentally constrained by vocoder performance. Experiments show that our model consistently produces high-fidelity 48 kHz audio across diverse upsampling factors, achieving state-of-the-art performance on both speech and general audio datasets.
Pipeline of UniverSR
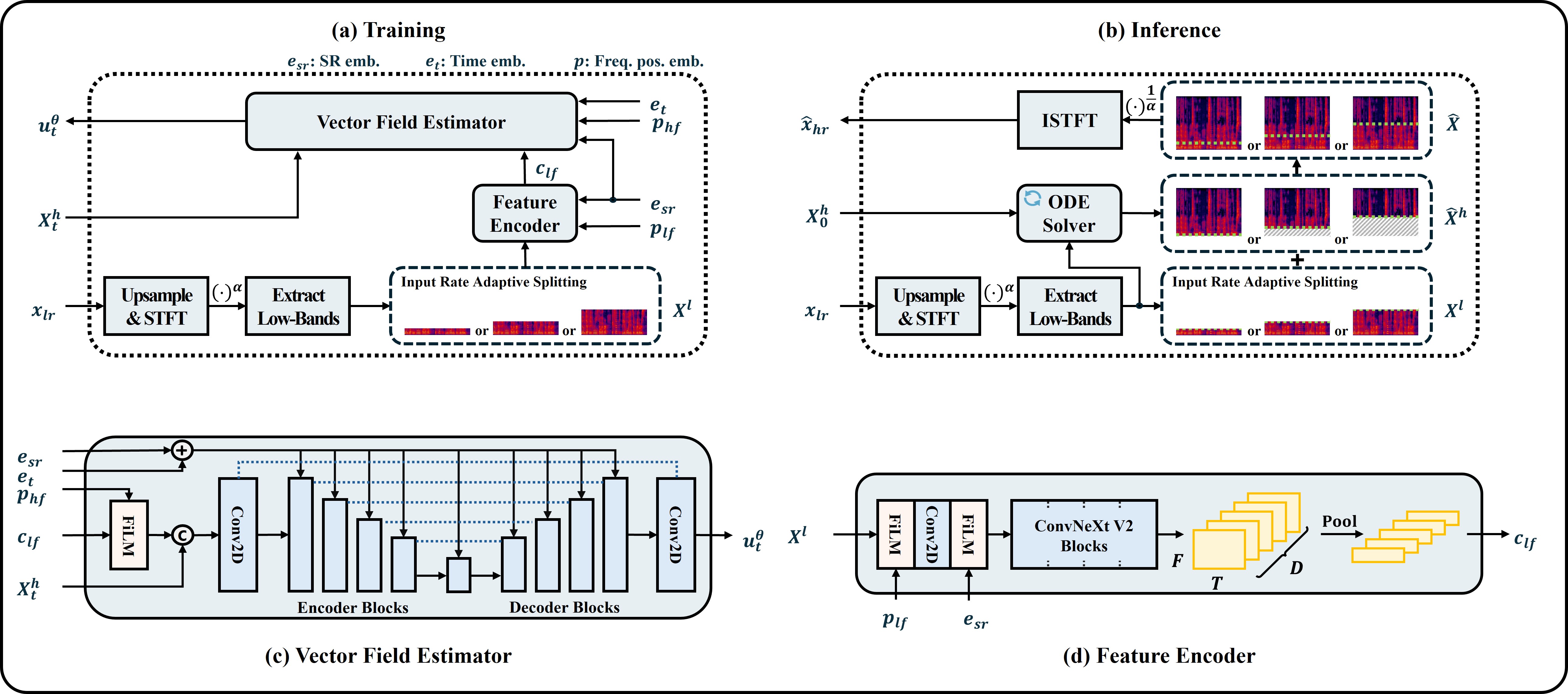
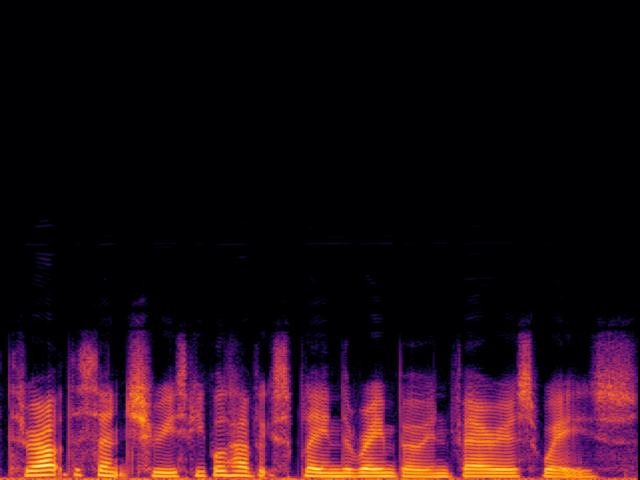
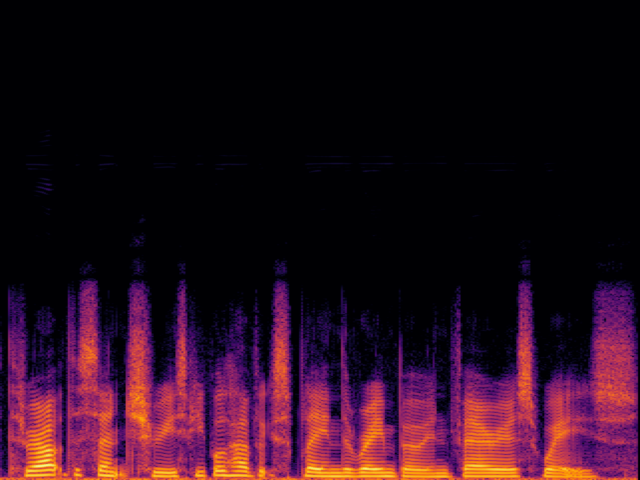
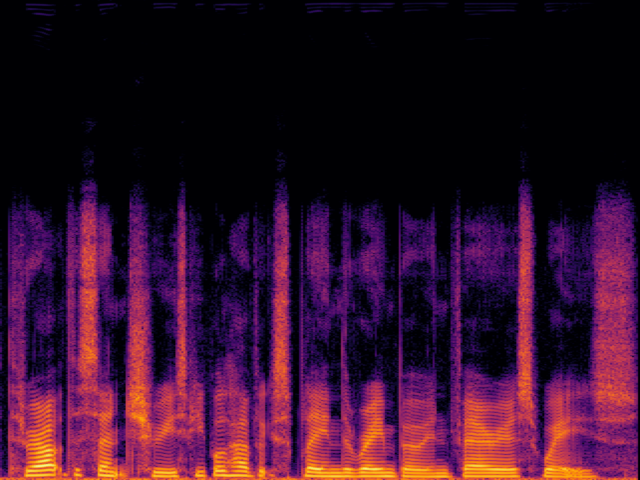
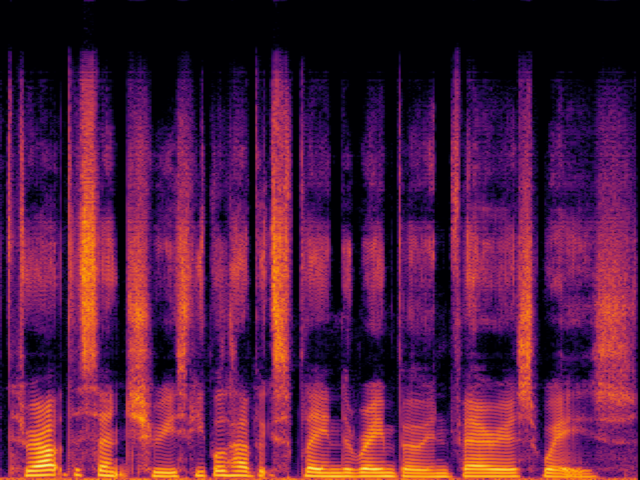
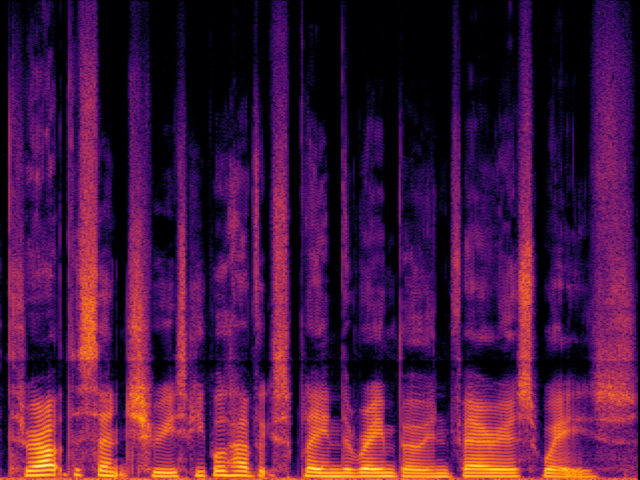
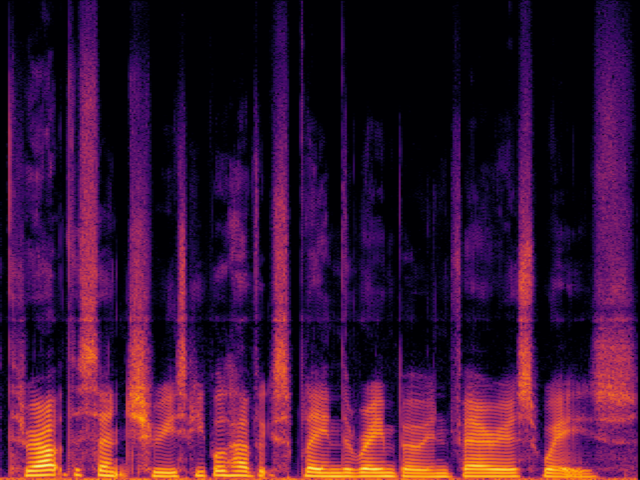
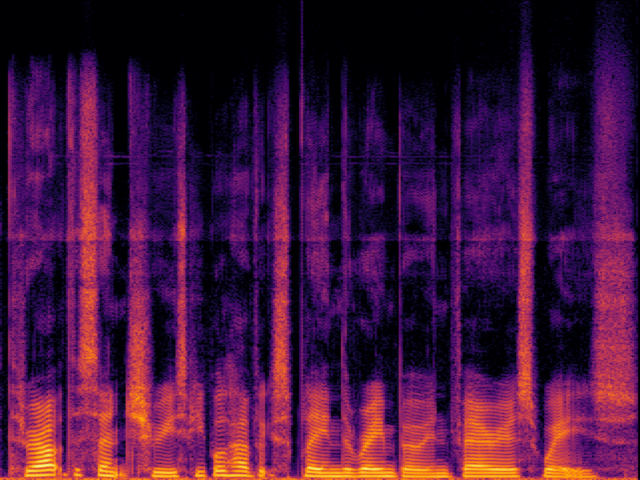
Audio Super Resoultion in Speech Domain
| Ground Truth | Ground Truth (Vocoded) |
|---|---|
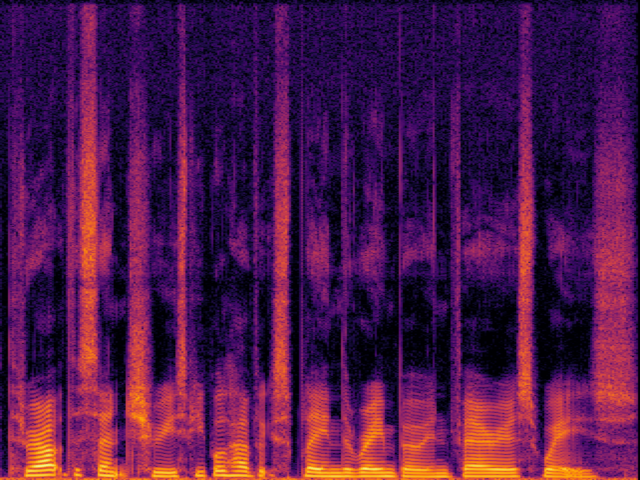
|
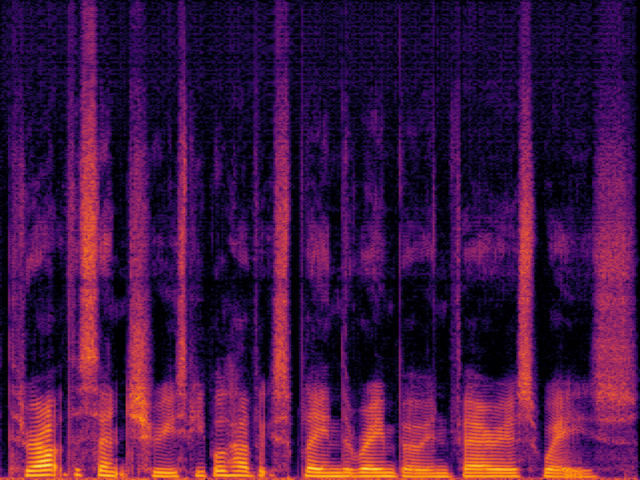
|
| 8 → 48 kHz | 12 → 48 kHz | 16 → 48 kHz | 24 → 48 kHz | |
|---|---|---|---|---|
| Input |
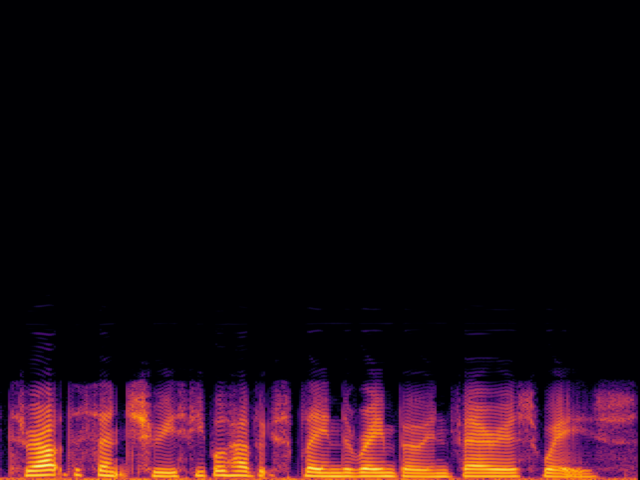
|
|
|
|
| AudioSR |
|
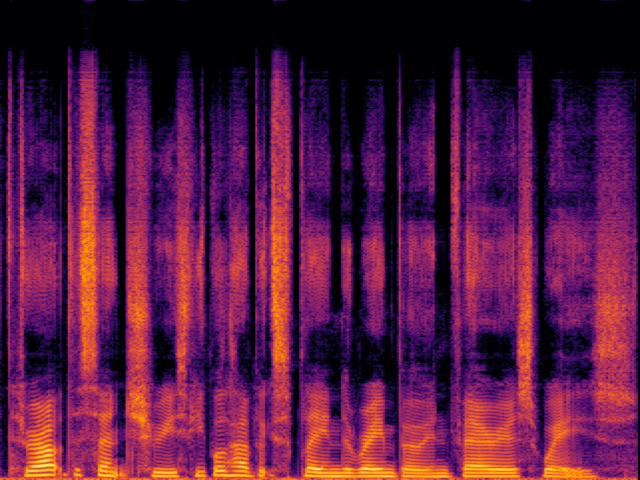
|
|
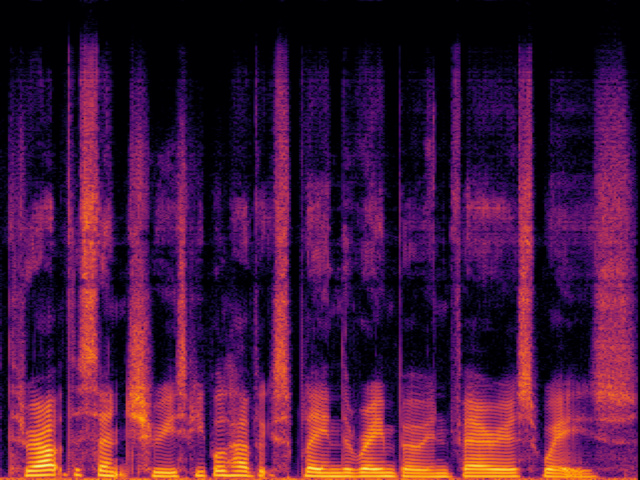
|
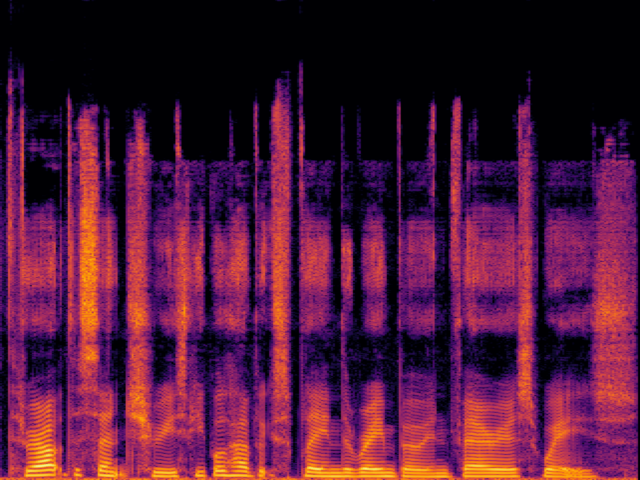
| FlashSR |
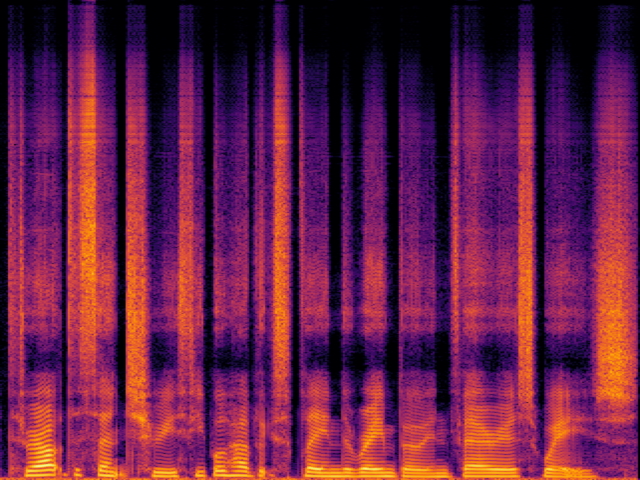
|
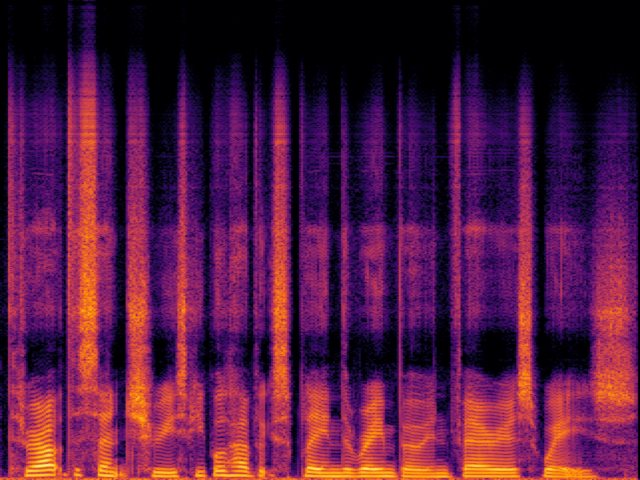
|
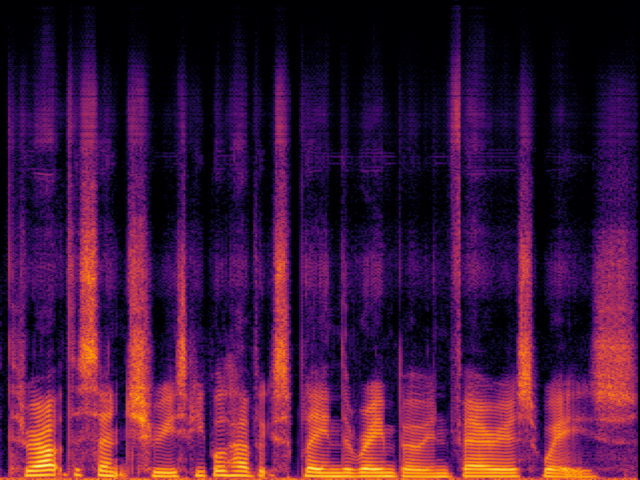
|
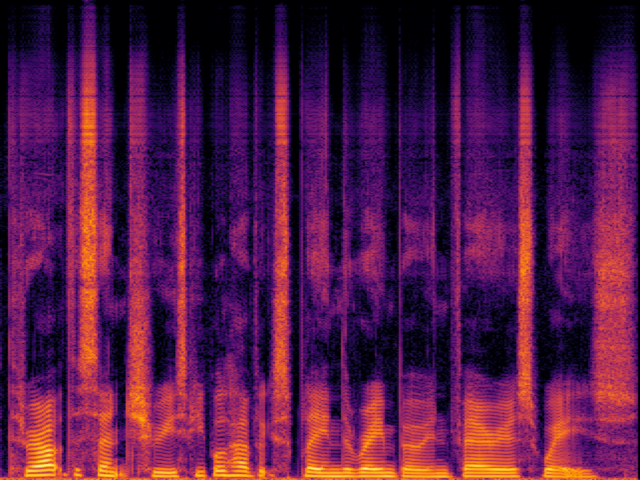
|
| UniverSR (Proposed) |
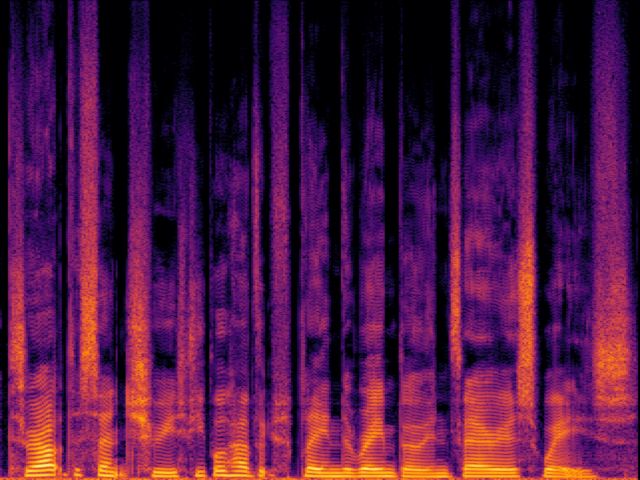
|
|
|
|
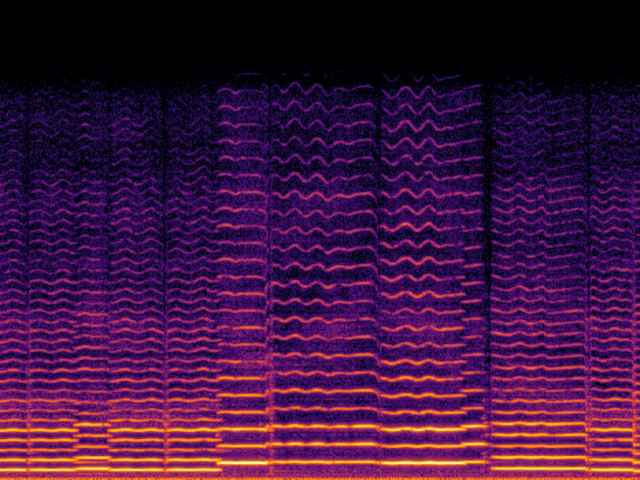
Audio Super Resoultion in Music Domain
| Ground Truth | Ground Truth (Vocoded) |
|---|---|
|
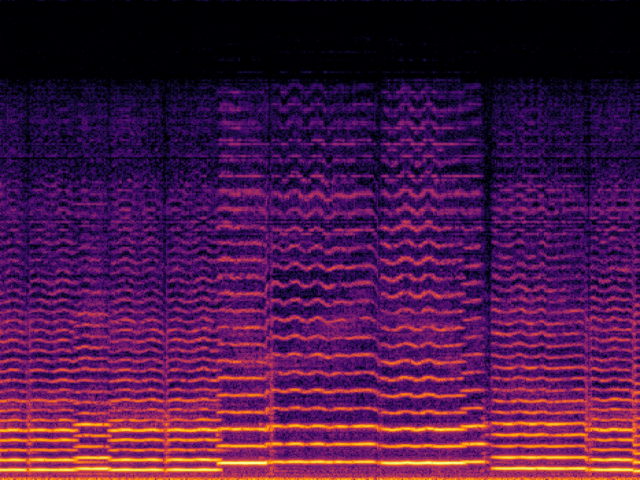
|
| 8 → 48 kHz | 12 → 48 kHz | 16 → 48 kHz | 24 → 48 kHz | |
|---|---|---|---|---|
| Input |
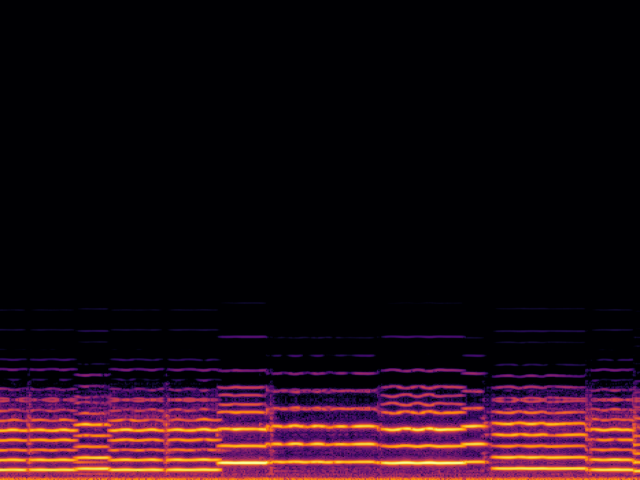
|
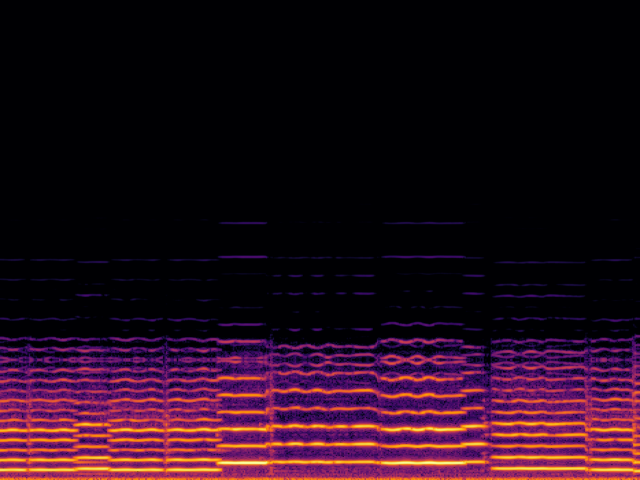
|
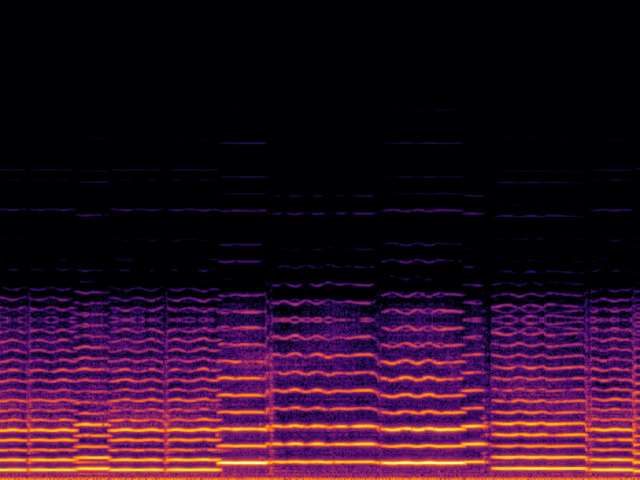
|
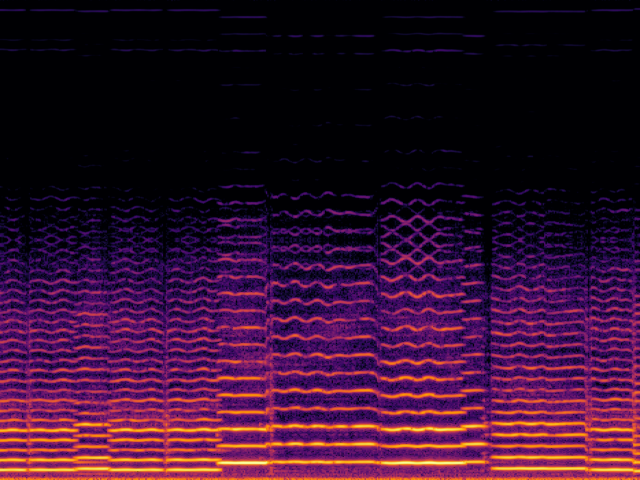
|
| AudioSR |
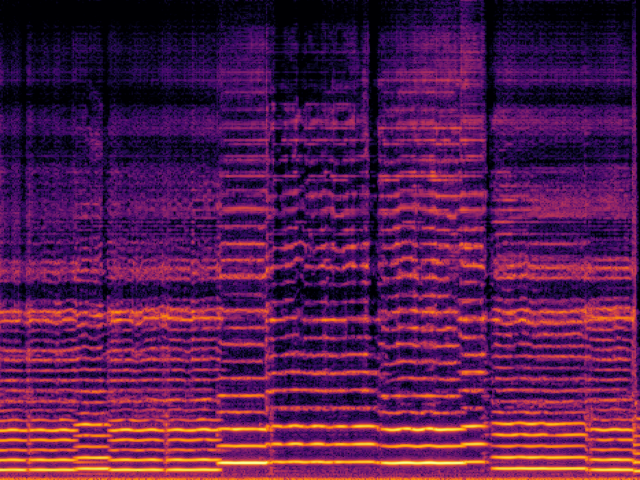
|
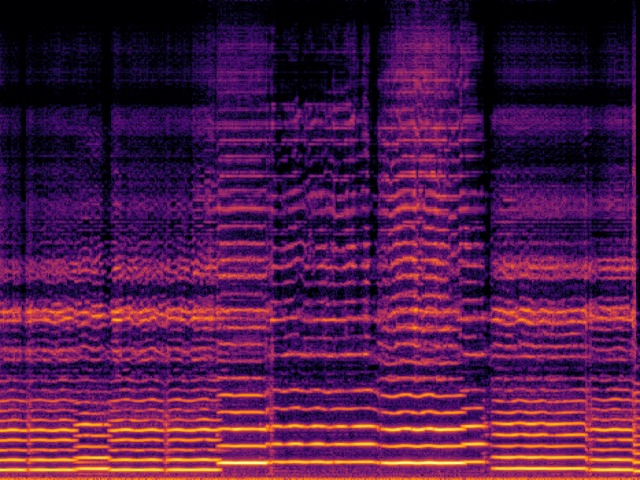
|
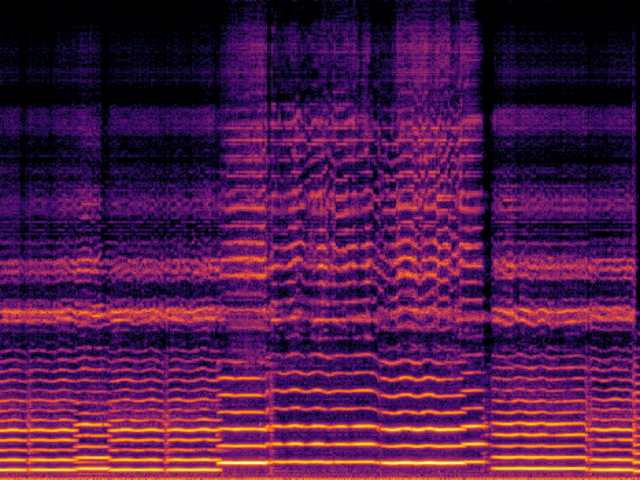
|
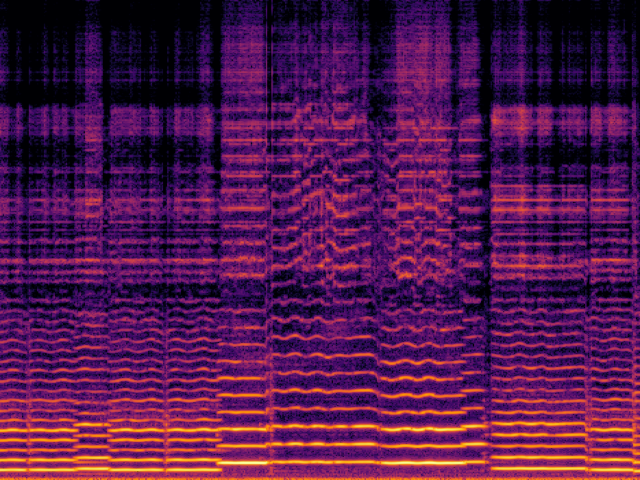
|
| FlashSR |
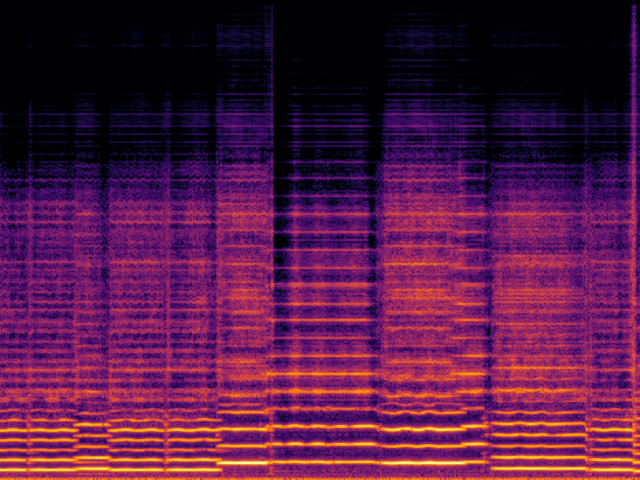
|
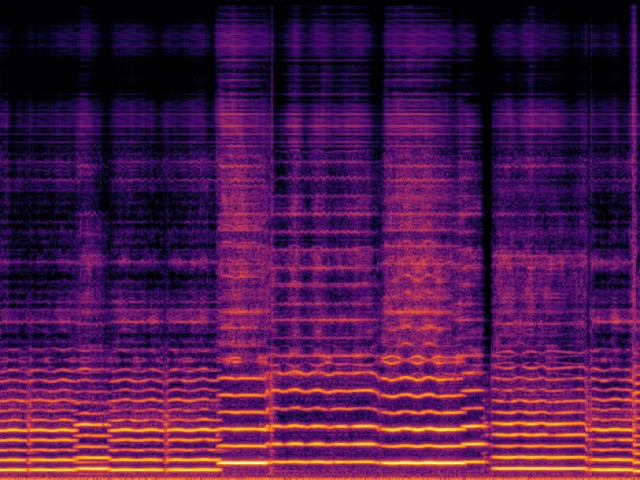
|
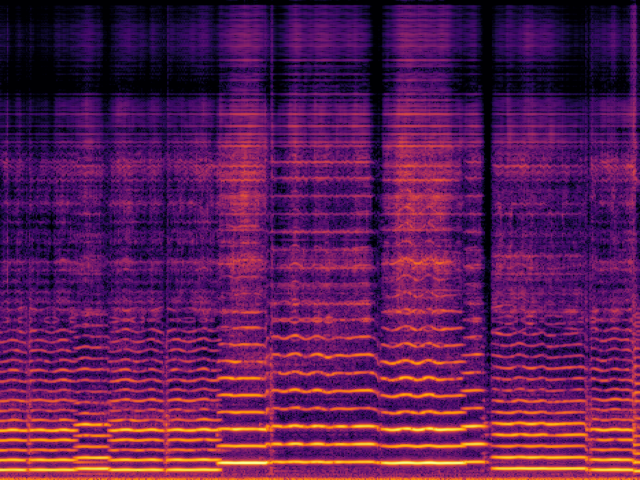
|
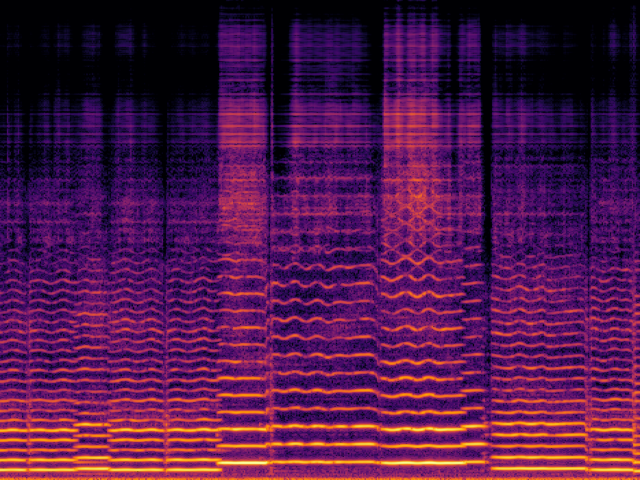
|
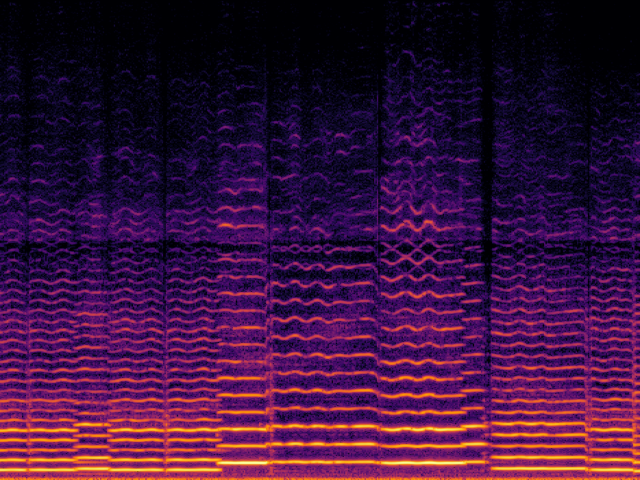
| UniverSR (Proposed) |
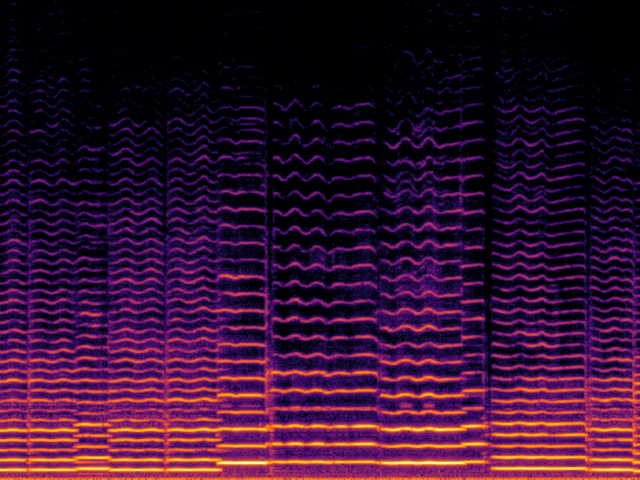
|
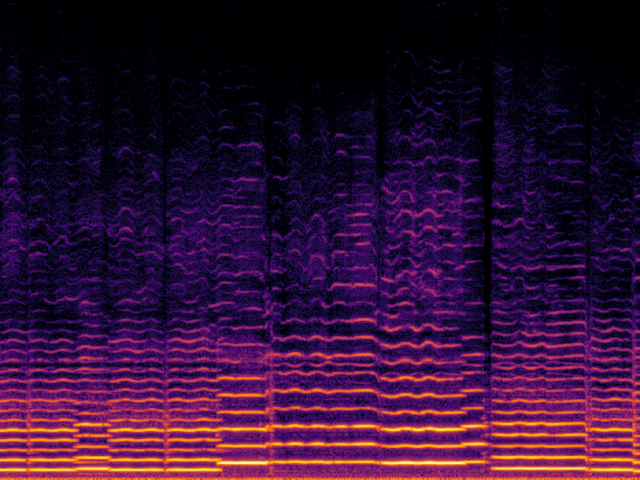
|
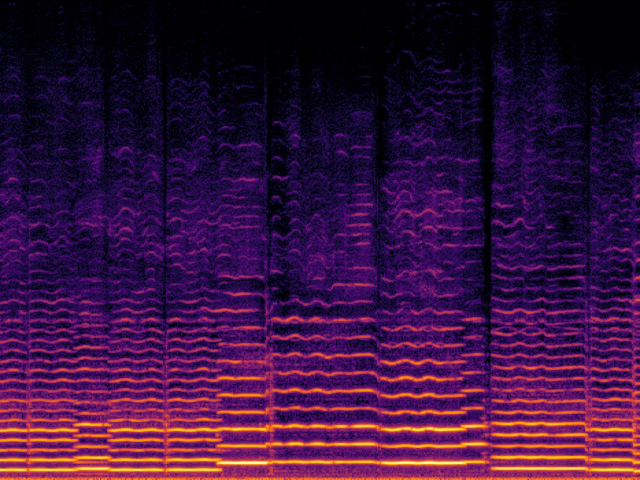
|
|
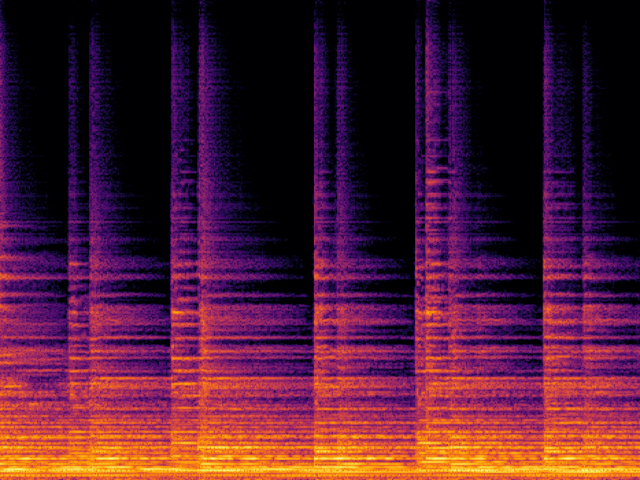
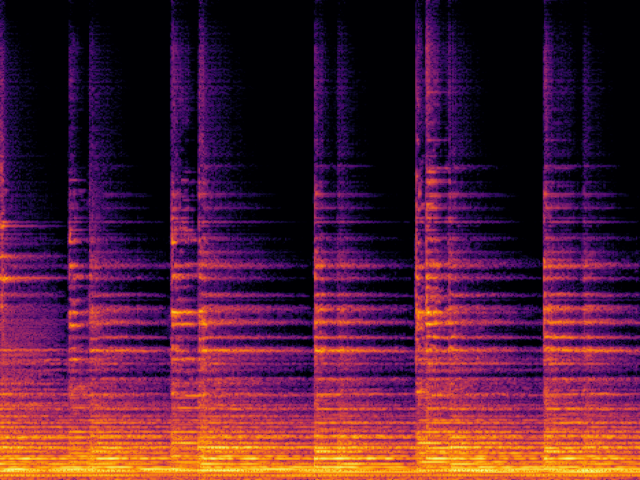
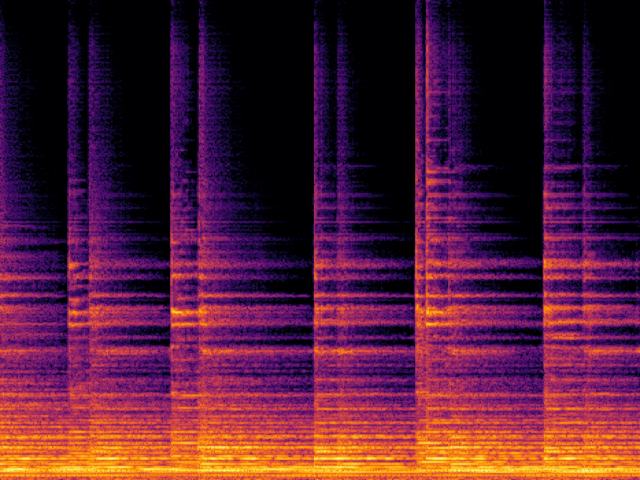
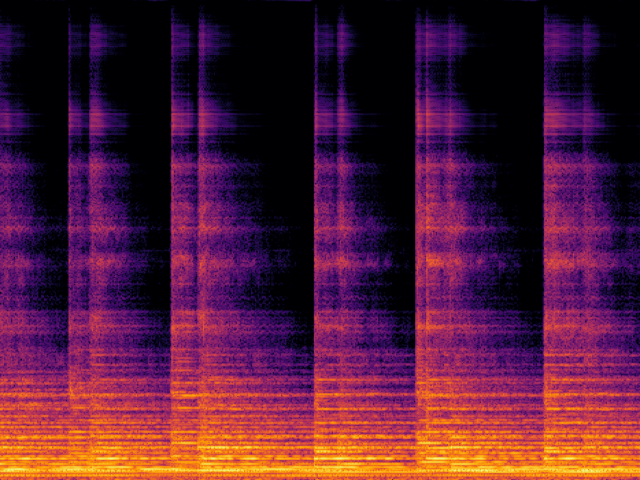
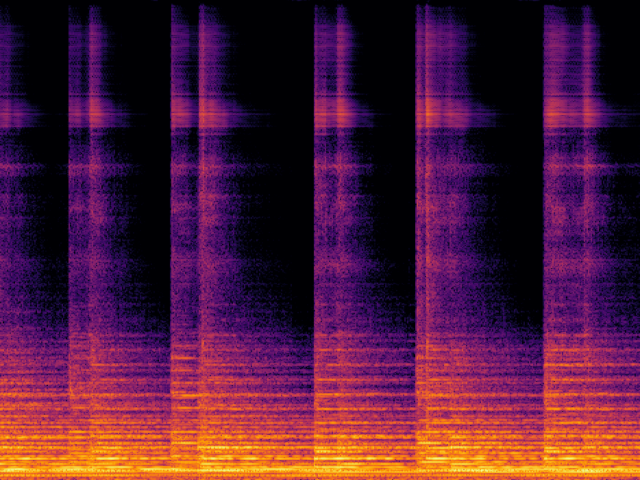
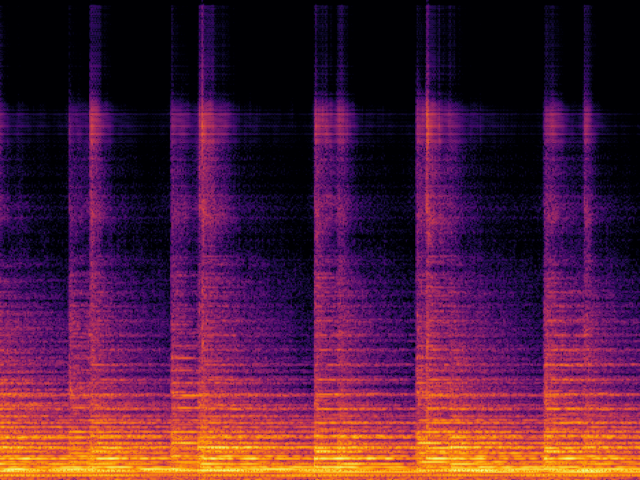
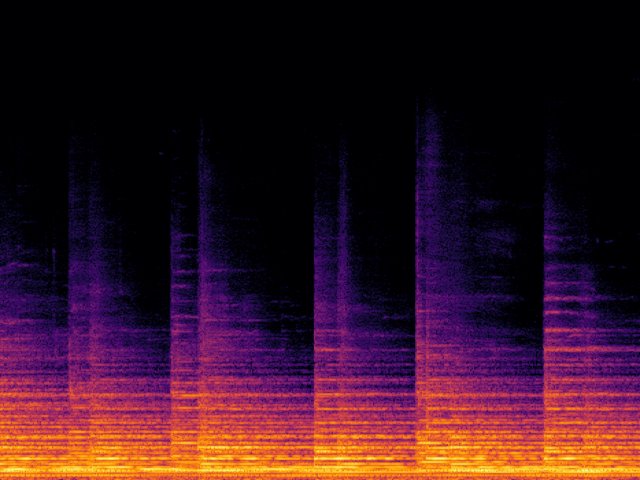
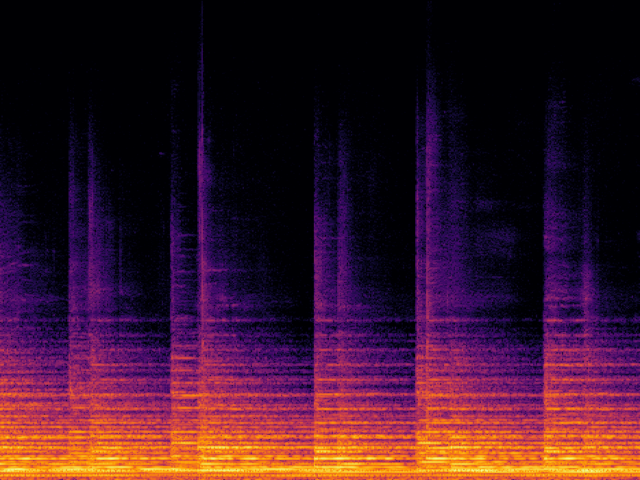
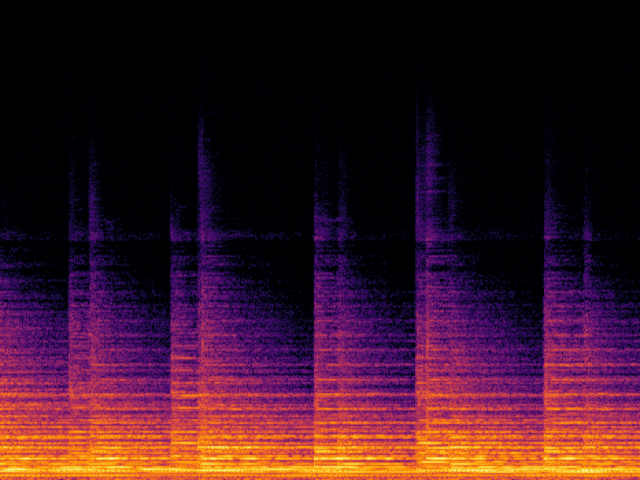
Audio Super Resoultion in Sound Effect Domain
| Ground Truth | Ground Truth (Vocoded) |
|---|---|
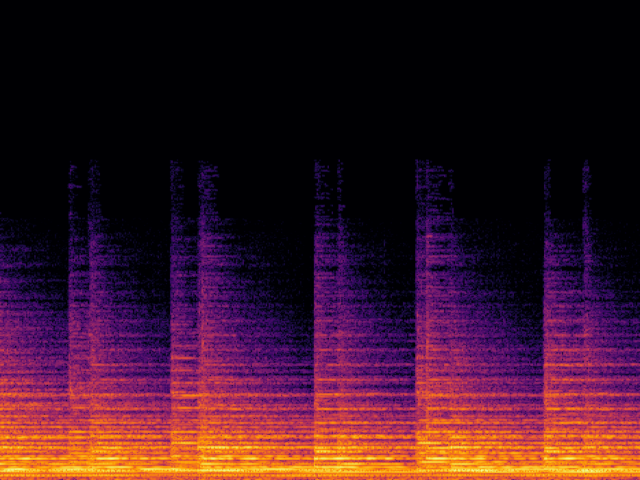
|
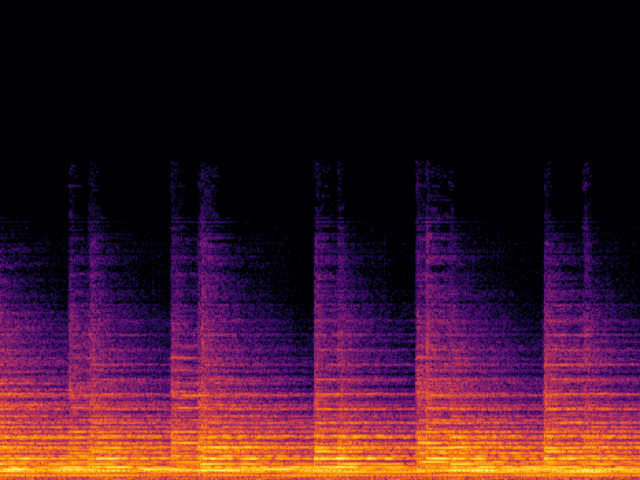
|
| 8 → 48 kHz | 12 → 48 kHz | 16 → 48 kHz | 24 → 48 kHz | |
|---|---|---|---|---|
| Input |
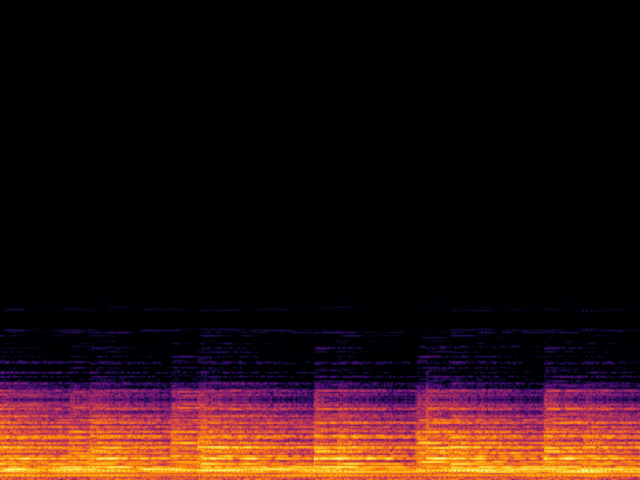
|
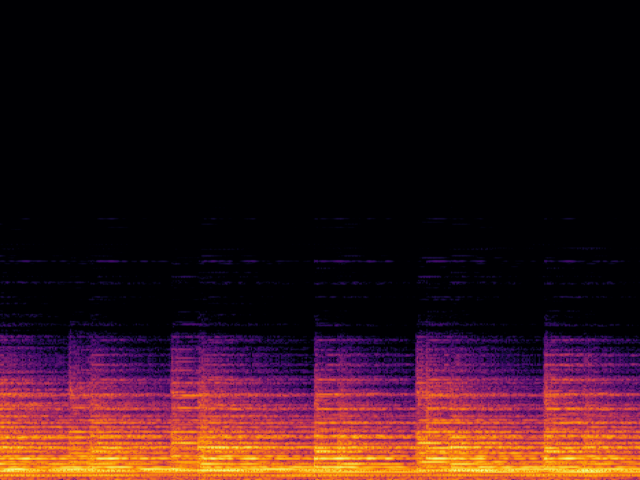
|
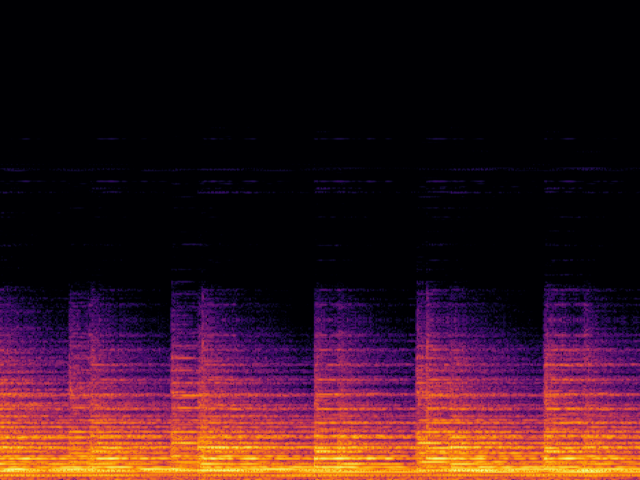
|
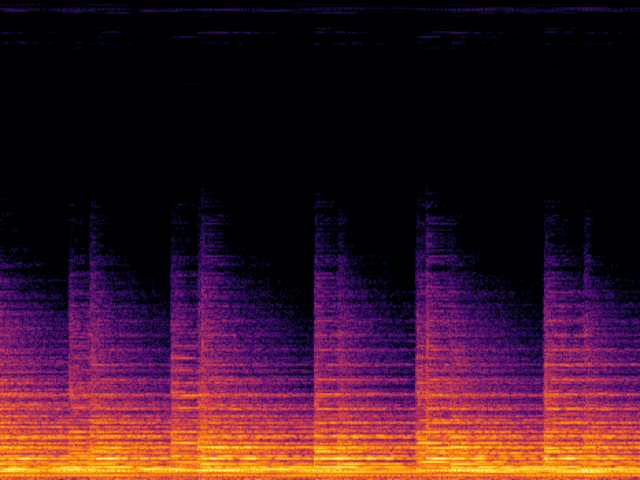
|
| AudioSR |
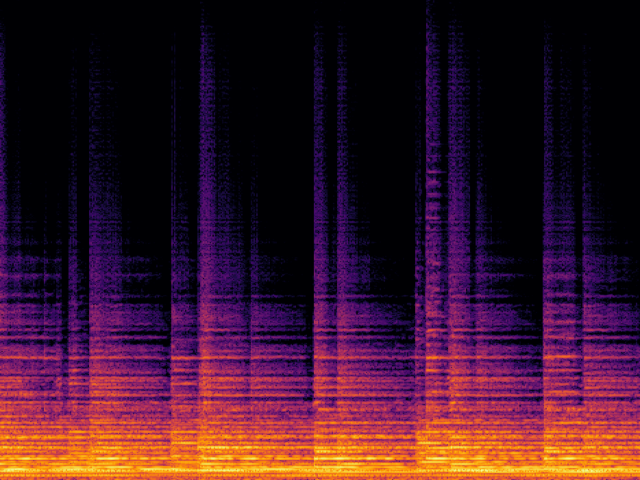
|
|
|
|
| FlashSR |
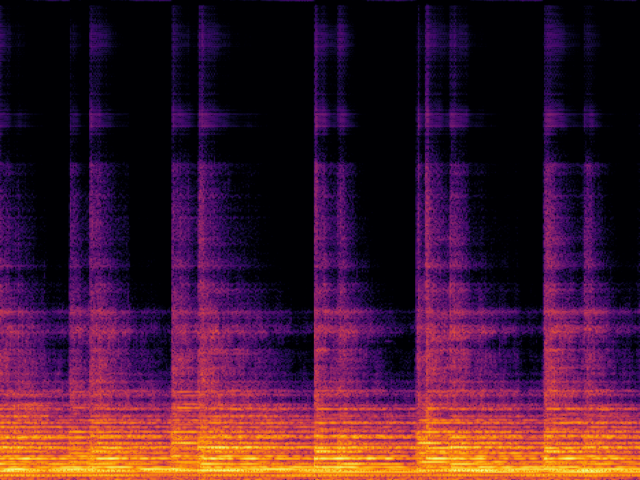
|
|
|
|
| UniverSR (Proposed) |
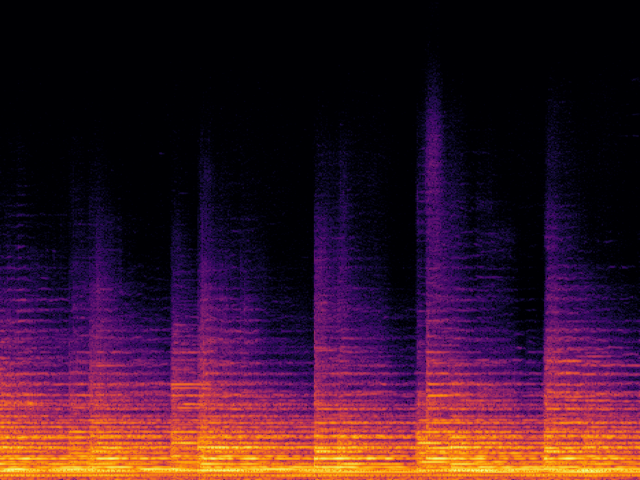
|
|
|
|
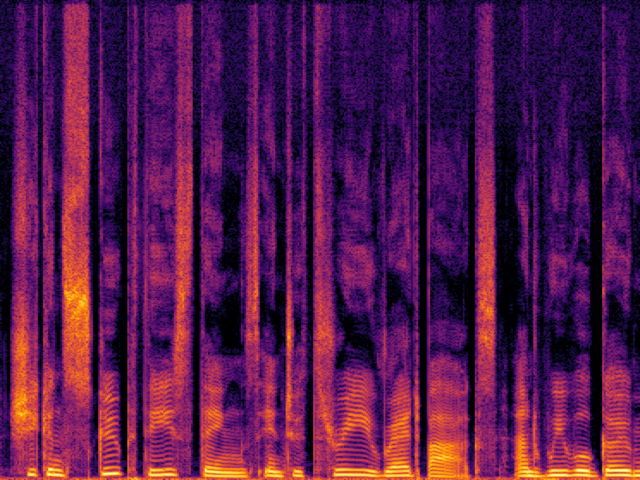
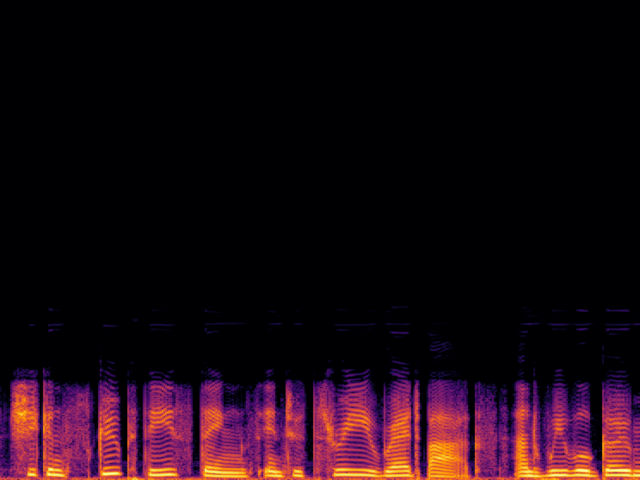
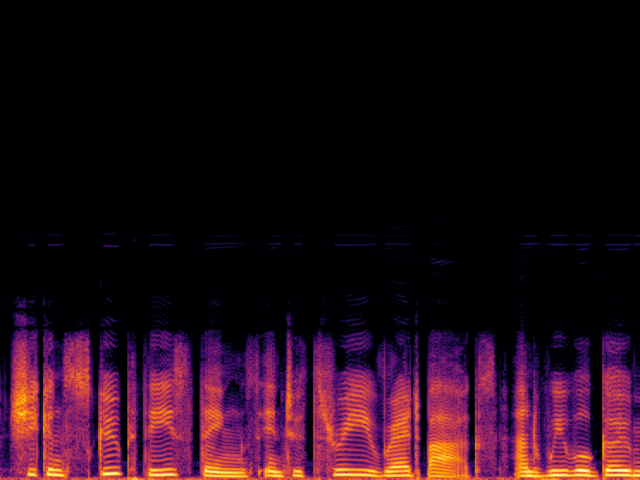
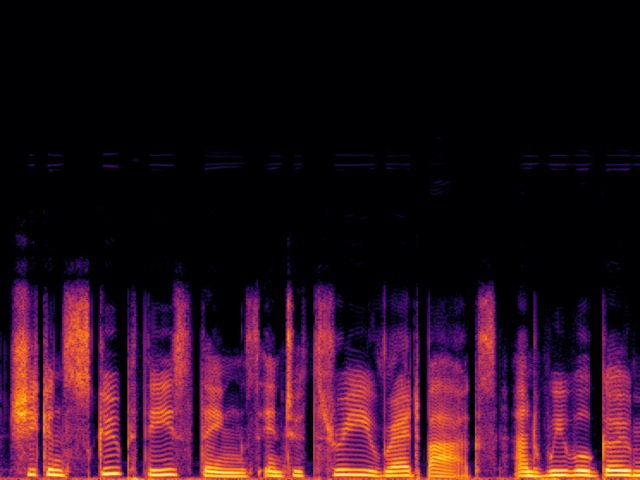
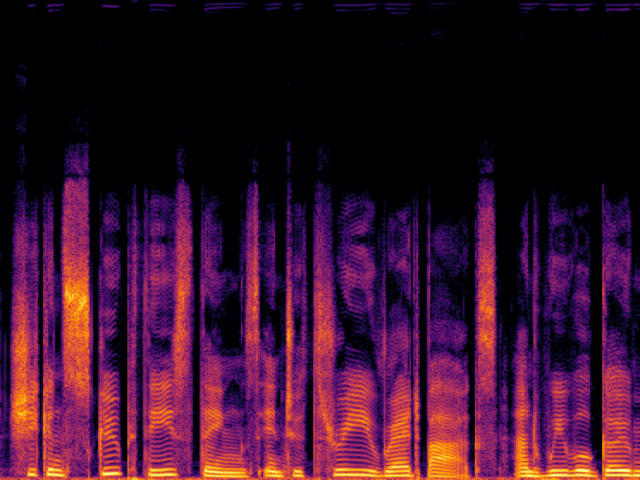
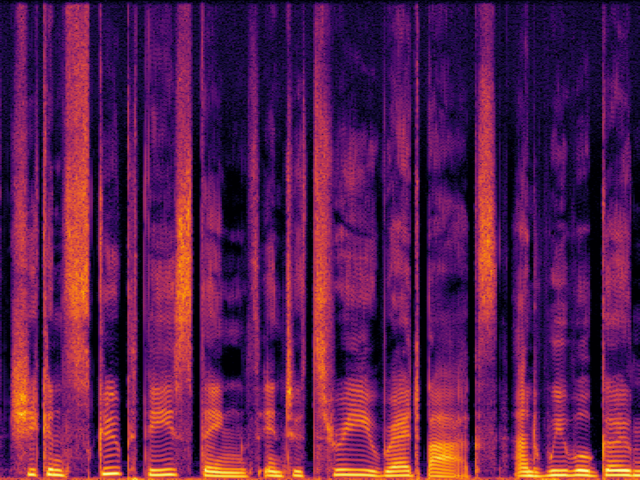
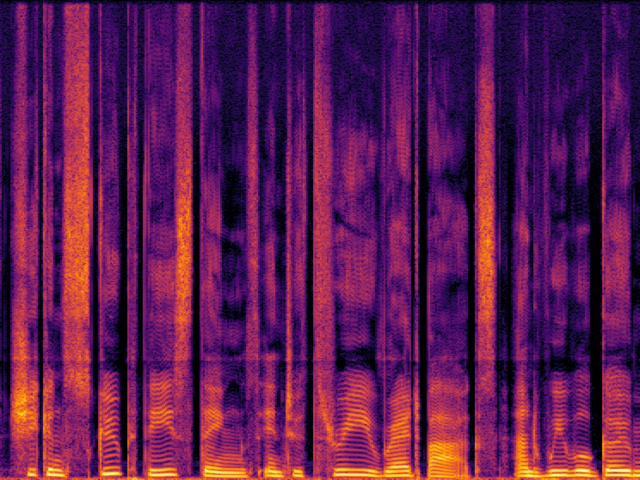
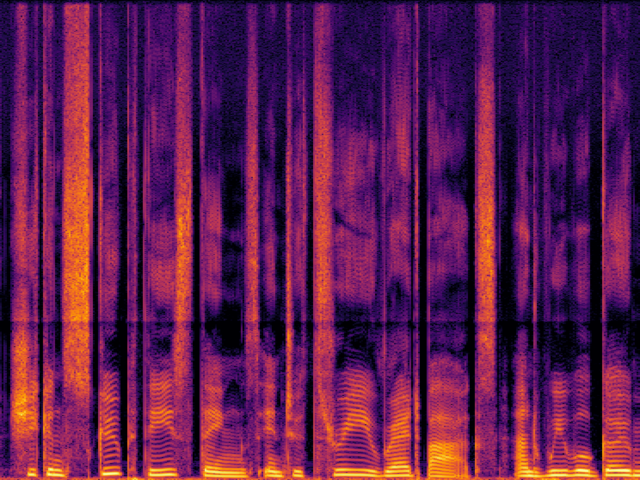
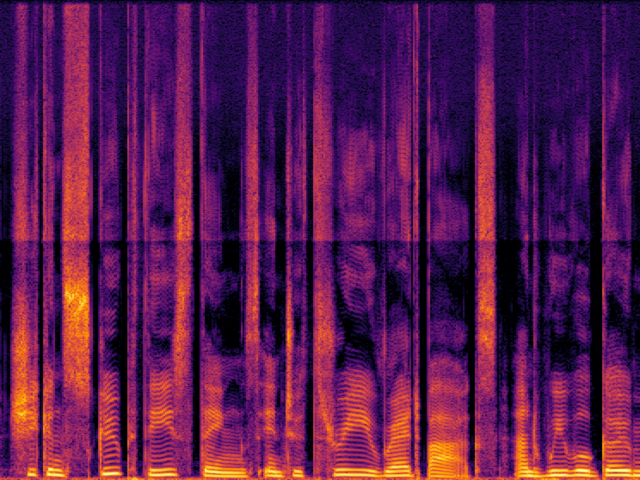
Comparison with Speech Super Resolution Models
| Ground Truth | Ground Truth (Vocoded) |
|---|---|
_8000.png)
|
|
| 8 → 48 kHz | 12 → 48 kHz | 16 → 48 kHz | 24 → 48 kHz | |
|---|---|---|---|---|
| Input |
|
|
|
|
| Fre-Painter |
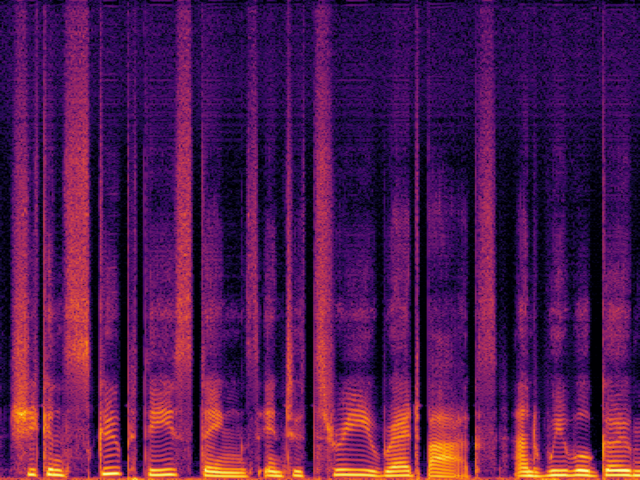
|
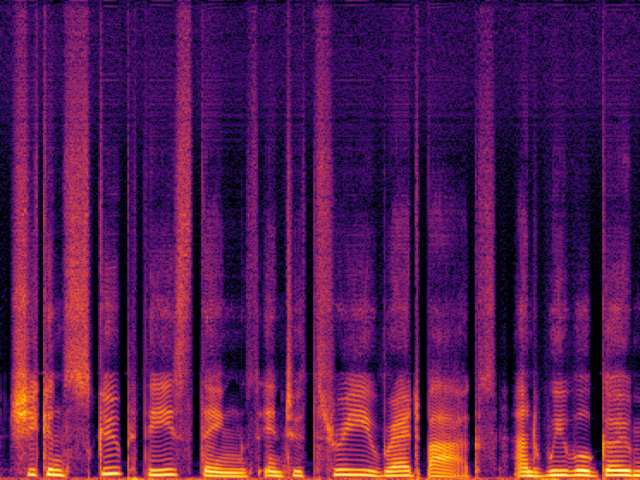
|
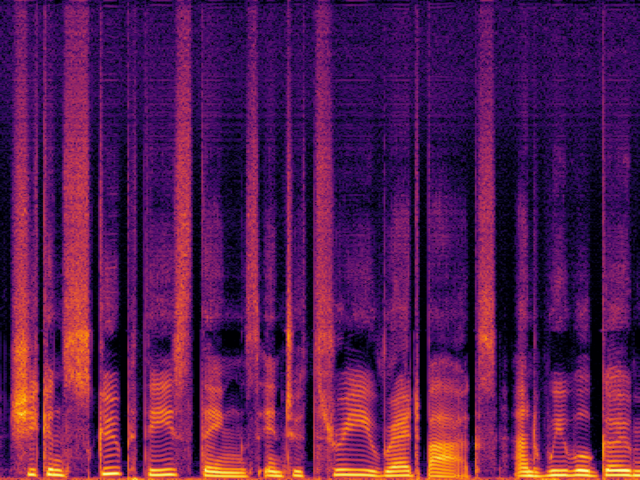
|
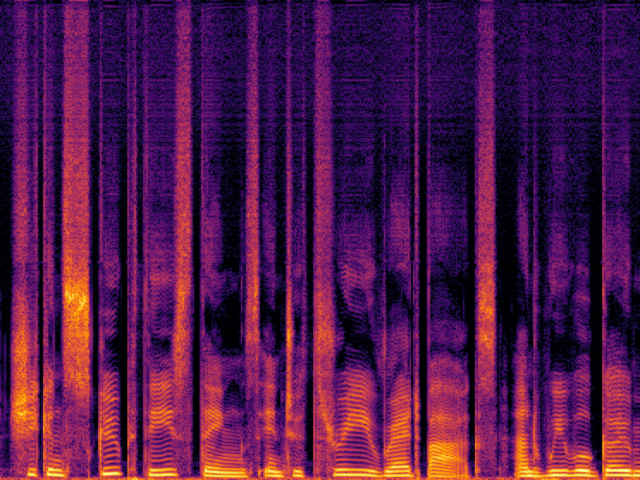
|
| FlowHigh |
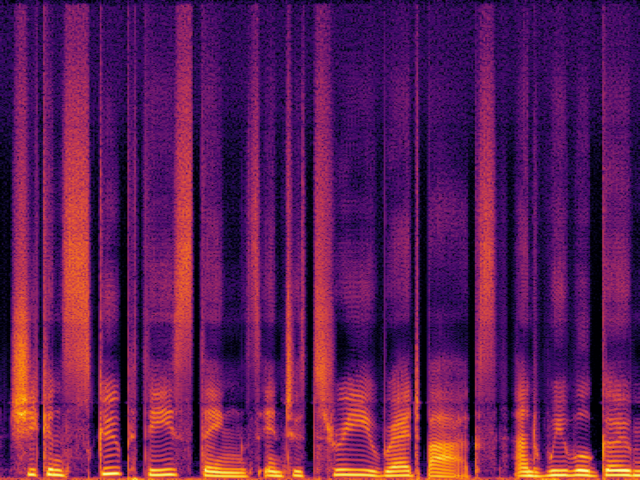
|
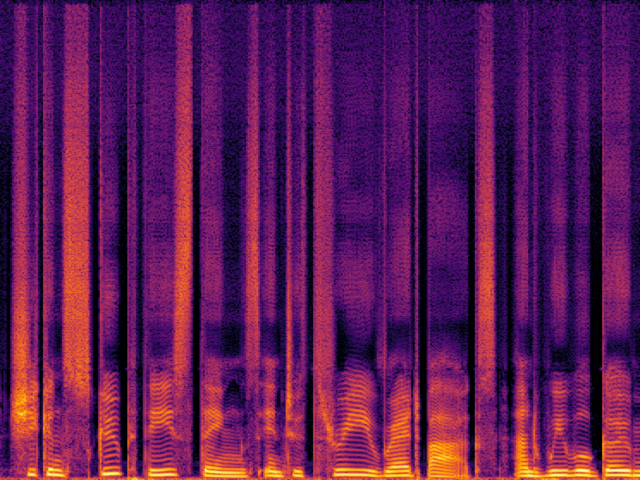
|
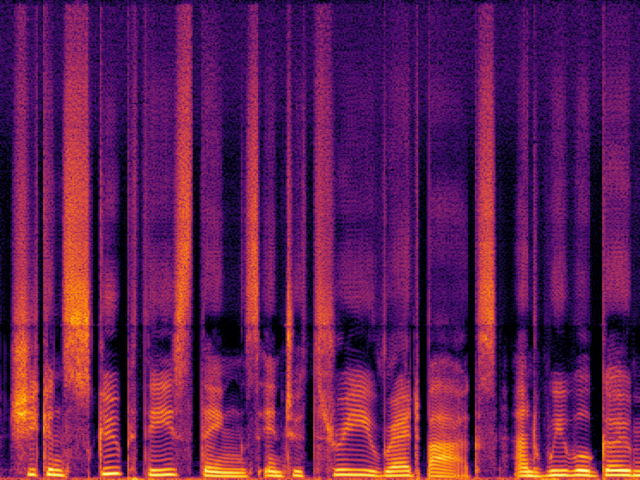
|
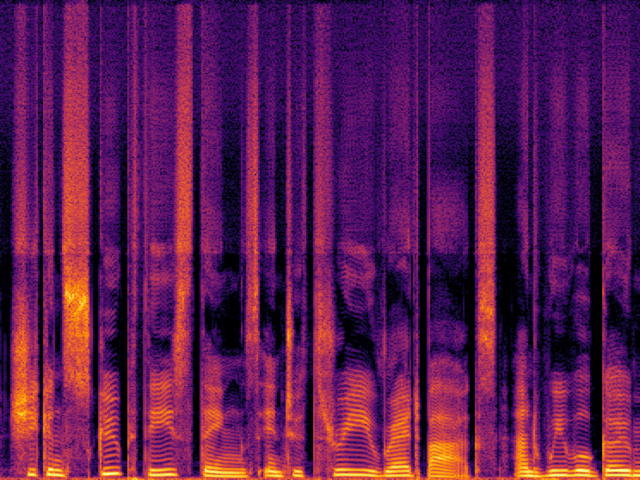
|
| NU-Wave2 |
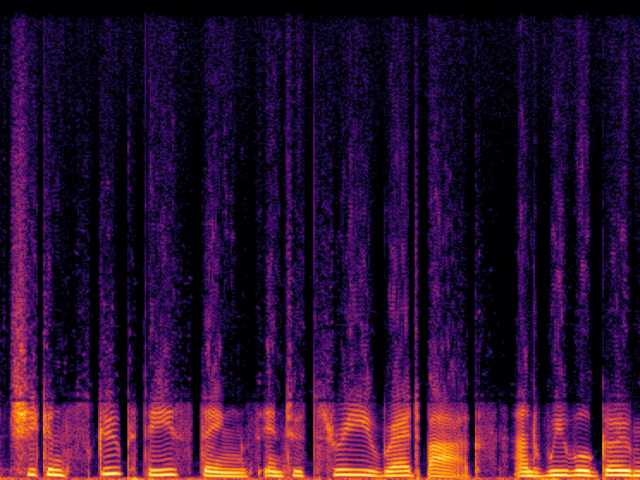
|
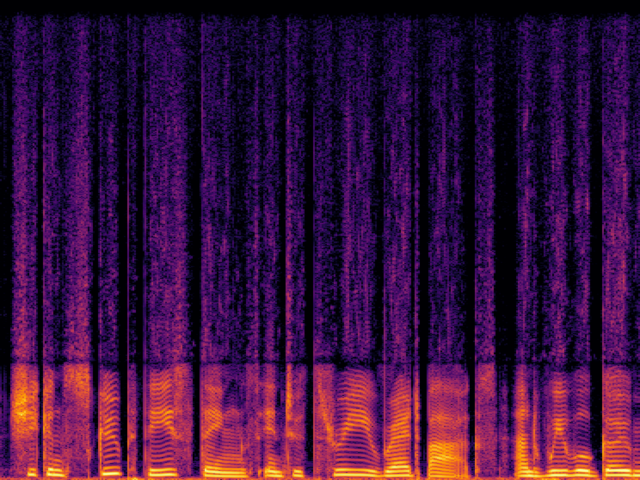
|
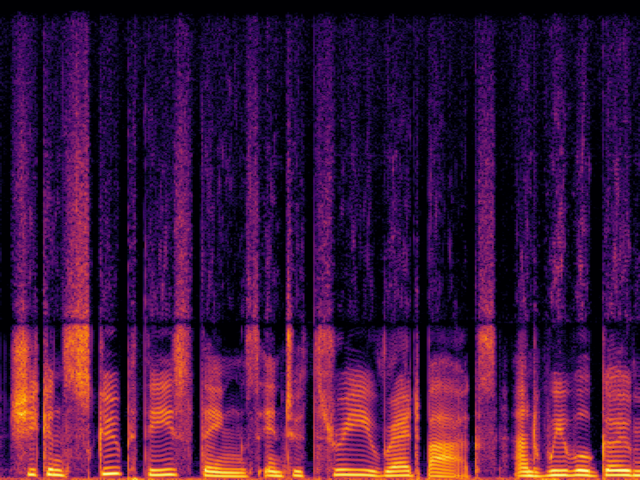
|
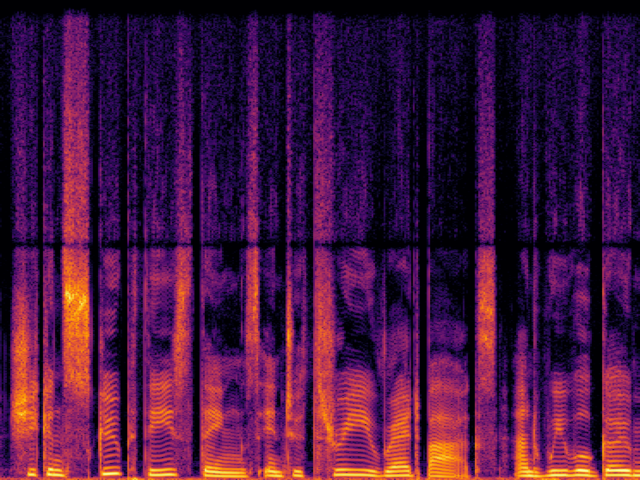
|
| UDM+ |
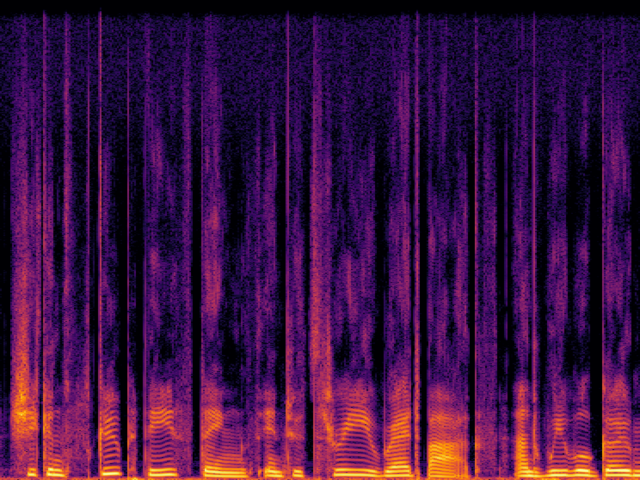
|
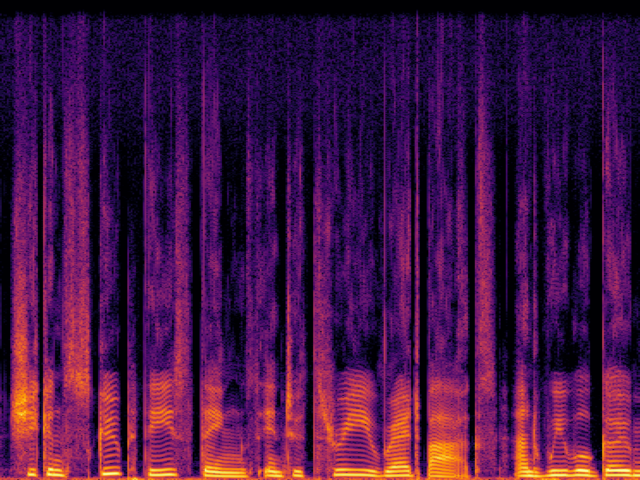
|
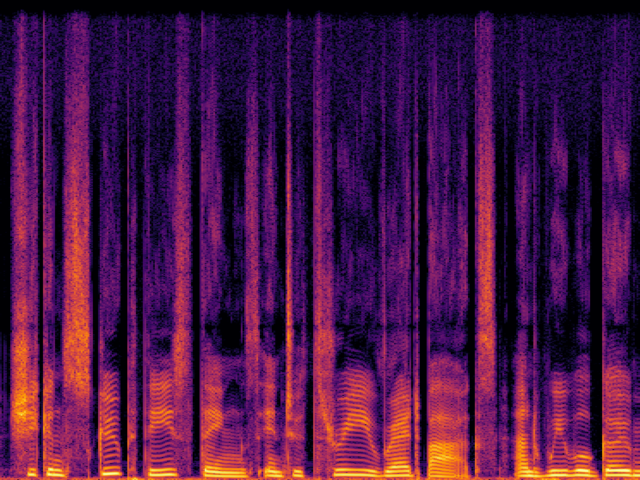
|
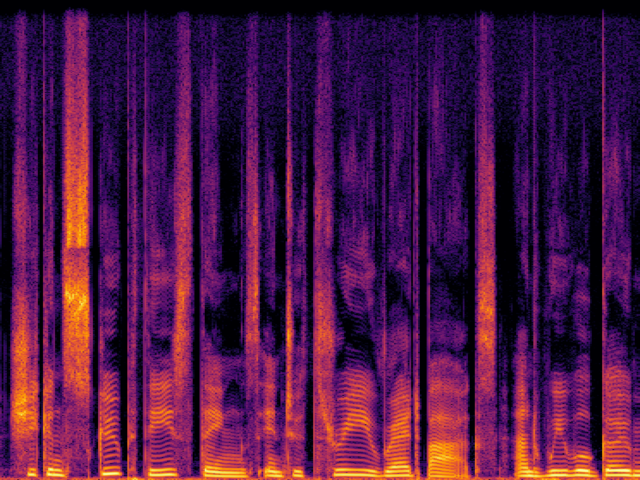
|
| UniverSR (Proposed) |
|
|
|
|